

The US Math Olympiad (USAMO) serves as a qualifier for the Worldwide Math Olympiad and presents a a lot increased bar than assessments just like the American Invitational Arithmetic Examination (AIME). Whereas AIME issues are troublesome, they require integer solutions. USAMO calls for contestants write out full mathematical proofs, scored for correctness, completeness, and readability over 9 hours and two days.
The researchers evaluated a number of AI reasoning fashions on the six issues from the 2025 USAMO shortly after their launch, minimizing any probability the issues had been a part of the fashions’ coaching information. These fashions included Qwen’s QwQ-32B, DeepSeek R1, Google’s Gemini 2.0 Flash Pondering (Experimental) and Gemini 2.5 Professional, OpenAI’s o1-pro and o3-mini-high, Anthropic’s Claude 3.7 Sonnet with Prolonged Pondering, and xAI’s Grok 3.
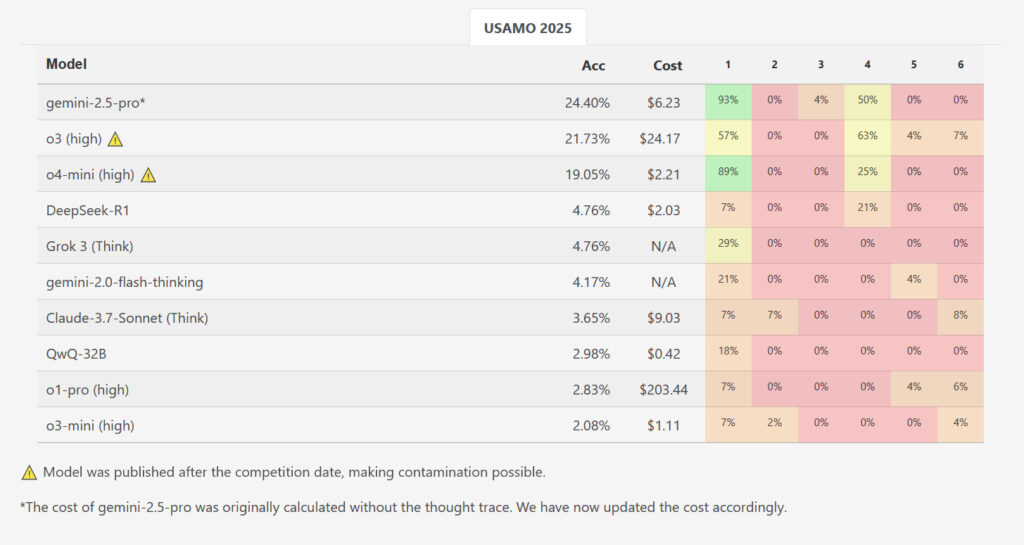
Whereas one mannequin, Google’s Gemini 2.5 Professional, achieved the next common rating of 10.1 out of 42 factors (~24 p.c), the outcomes in any other case confirmed a large efficiency drop in comparison with AIME-level benchmarks. The opposite evaluated fashions lagged significantly additional behind: DeepSeek R1 and Grok 3 averaged 2.0 factors every, Google’s Flash-Pondering scored 1.8, Anthropic’s Claude 3.7 managed 1.5, whereas Qwen’s QwQ and OpenAI’s o1-pro each averaged 1.2 factors. OpenAI’s o3-mini had the bottom common rating at simply 0.9 factors (~2.1 p.c). Out of practically 200 generated options throughout all examined fashions and runs, not a single one obtained an ideal rating for any downside.
Whereas OpenAI’s newly launched 03 and o4-mini-high weren’t examined for this research, benchmarks on the researchers’ MathArena web site present o3-high scoring 21.73 p.c general and o4-mini-high scoring 19.05 p.c general on USAMO. Nonetheless, these outcomes are doubtlessly contaminated as a result of they had been measured after the competition befell, which means that the newer OpenAI fashions might doubtlessly have included the options within the coaching information.
How the fashions failed
Within the paper, the researchers recognized a number of key recurring failure patterns. The AI outputs contained logical gaps the place mathematical justification was missing, included arguments primarily based on unproven assumptions, and continued producing incorrect approaches regardless of producing contradictory outcomes.
A selected instance concerned USAMO 2025 Drawback 5. This downside requested fashions to seek out all optimistic entire numbers “okay,” such {that a} particular calculation involving sums of binomial coefficients raised to the facility of “okay” would all the time end in an integer, irrespective of which optimistic integer “n” was used. On this downside, Qwen’s QwQ mannequin made a notable error: It incorrectly excluded non-integer potentialities at a stage the place the issue assertion allowed them. This error led the mannequin to an incorrect closing reply regardless of having appropriately recognized the mandatory situations earlier in its reasoning course of.


